| Xara Xtreme for Linux is a powerful, general purpose graphics program for Unix platforms including Linux, FreeBSD and (in development) OS-X. Formely known as Xara LX, it is based on Xara Xtreme for Windows, which is the fastest graphics program available, period. The Xara Xtreme source code was made available open-source in early 2006, and is being ported to Linux. This process is almost complete and Xara Xtreme for Linux is available for download now.
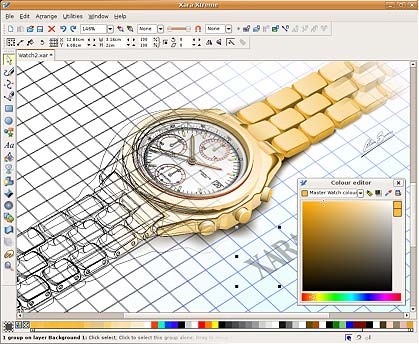
Xara Xtreme for Linux:
- Is very fast, very slick to use.
- Offers some of the most powerful graphics tools available.
- Is simple to use and learn.
- Has a clean, un-cluttered user interface. Few floating dialogs, palettes, menus etc.
- Is able to create a huge range of outstanding graphics.
- Has a huge resource of learning material, tutorials, movies, tips and a very active enthusiastic and growing user community.
"Xara LX promises to be the most important gift from the proprietary world to free software since OpenOffice.org."
Linux.com - read the review
"Could Xara Xtreme become the StarOffice/OpenOffice.org of the graphics world? We won’t be betting against it."
.net
"With its amazing speed, small size, reasonable system requirements, moderate price and powerful feature set, it’s hard to go wrong with Xara Xtreme. Xara’s recent announcements to make Xtreme open source and to develop Mac and Linux version should only make this excellent product even better."
About.com
|  | Xara Cloud The world’s smartest document creator
Create visual and engaging business and marketing documents that work in minutes - no design experience required. Xara Xone Years of tutorials for beginners and advanced users. Featured artists and a lot more. Xara Xtreme Forums Our loyal, enthusiastic users are usually happy to help or answer any question. Xara Xtreme Tip of the week A large collection of useful tips. Xara Xtreme for Windows home The Linux version is almost identical to the Windows version. Here you can find out more about what it can do Xara Outsider newsletter View past editions and subscribe to our new monthly newsletter |
|
|
Last Updated ( Monday, 20 October 2008 14:20 )
|

